Descripción
Debido al auge que tuvo el campo de la Recuperación de Información o Information Retrieval en inglés, resultó necesario la investigar en nuevos métodos de compresión que facilitaran el trabajo con documentos con contenido en lenguaje natural, ya que las técnicas tradicionales ofrecían resultados poco satisfactorios.
Aunque David A. Huffman en su trabajo original planteo la posibilidad de utilizar árboles n-arios en lugar de binarios para construir la codificación, lo que en principio es la idea de fondo en las técnicas orientadas a bytes, no profundizó en el tema.
No obstante, en el año 2000, Ricardo Baeza-Yates, Edleno Silva de Moura, Gonzalo Navarro y Nivio Ziviani, su artículo Fast and flexible word searching on compressed text plantearon dos métodos orientados a bytes y a palabras, esta última característica resulta muy decuada si se toma en cuenta que en el campo de la R.I. los átomos o unidades mínimas de trabajo son los términos o palabras, no caracteres aislados. Estos métodos se revisarán más adelante.
La principal diferencia entre los métodos orientados a bytes y los métodos orientados a bits, es que los primeros asignan bytes completos en la codificación, en lugar de bits y utilizan arboles n-earios, donde n es comunmente una potencia de 2, pero por lo demás, el proceso de construcción de los códigos es el mismo.
En el caso de los dos métodos presentados aquí, se utiliza un enfoque semi-estático para obtener las frecuencias de los términos.
Ventajas de los métodos orientados a
bytes
Los métodos de compresión orientados a bytes, especificamente los tratados aquí, ofrecen una serie de características muy atractivas. A continuación se listan algunas mencionadas por los autores en su trabajo:
- Posibilidad de descomprimir porciones arbitrarias de un texto de manera eficiente.
- Posibilidad de realizar búsqueda exacta de palabras y frases, utilizando cualquier algoritmo de busqueda secuencial conocido, sin necesidad de descomprimir el texto.
- Posibilidad de realizar búsquedas de aproximación basadas en palabras, de manera eficiente y sin necesidad de descomprimir el texto.
-Acceso aleatorio al texto comprimido.
-La búsuqueda de palabras sencillas o frases, se realiza hasta dos veces más rápido en el texto comprimido que en el mismo texto sin comprimir.
-En general, se da un relación ganacia - ganancia. Se gana en espacio, por la compresión del texto y en tiempo, ya que las búsquedas se realizan más rápidamente.
-Se plantea además la posibilidad de mantener los textos siempre comprimidos, siendo necesario la descompresión solo en caso de que se requiera desplegar la información.
Plain Huffman
El primero de los algoritmos presentados se conoce como Plain Huffman.
En este caso se utiliza un árbol con grado 256 para generar los códigos. Todos los bits de cada byte se utilizan en la codificación (no se utilizan bits como marcas o banderas, al contrario de Tagged Huffman)
Debido a que se utilizan los 8 bits de cada byte en la codificación, la tasa de compresión es superior a la de otro algoritmos que utilizan bits como banderas. Sin embargo, esta característica tiene un impacto negativo en las búsquedas, ya que es necesario el uso de algoritmos más complejos, basados en autómatas, lo que retrasa en cierta medida las búsquedas.
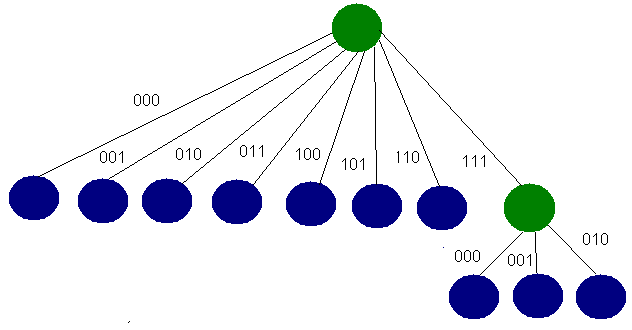
Ejemplo de árbol generado por el algortimo Plain Huffman. Para simplificar se
utilizan "bytes" de 3 bits.
Los nodos azules corresponden a los símbolos
iniciales, los verdes corresponden a nodos intermedios
Tagged Huffman
En este algoritmo se emplea un árbol de grado 128 para generar los
códigos. Esto debido a que se reserva 1 bit de cada byte para utilizarse como
marca o bandera que indica si es el inicio de un código o no.
Debido a lo anterior,
los códigos generados por este algoritmo, son más largos que los generados por
Plain Huffman, lo que afecta negativamente la tasa de compresión.
No
obstante estas banderas permiten búsquedas en el texto comprimido de manera
sencilla, rápida y eficiente, permitiendo incluso el uso de algortimos básicos
de búsqueda de patrones, ya que se elimina el problema de los falsos aciertos,
los cuáles se pueden dar cuando el final de un código unido al incio de otro
código, forman un código válido para otro símbolo, como se muestra a
continuación:

Pese a que por definición, la construcción del árbol Huffman asegura que ningún código generado puede ser prefijo de otro, este, por si mismo, no asegura que no se presente el caso anterior.
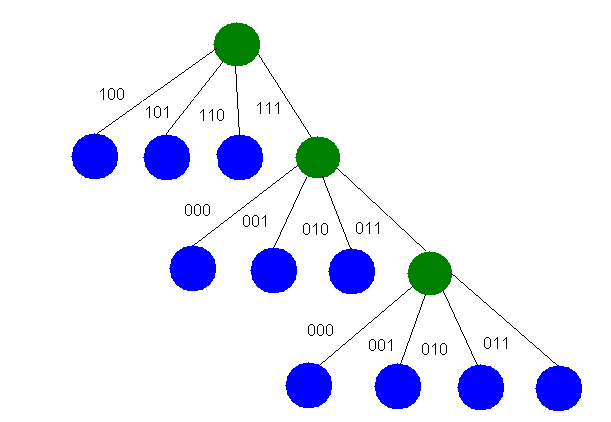
Ejemplo de árbol generado por el
algortimo Tagged Huffman. Para simplificar se utilizan "bytes" de 3 bits.
Los nodos azules corresponden a los
símbolos iniciales, los verdes corresponden a nodos intermedios
En el ejemplo anterior se observa como todos los bytes del segundo nivel del árbol empiezan con 1, pues indica el incio del código. En los siguientes niveles, los bytes inician con 0, ya que no corresponden al inicio del código.